The things ChatGPT won’t do fall into two buckets, and knowing which one you’ve hit saves a lot of wasted retries. A short list is a hard no: sexual content, real weapons, working malware, the stuff OpenAI’s rules will never allow no matter how politely you ask. The longer list is false alarms, harmless requests that pattern-match to something risky, where a small reword usually gets you straight through. I ran seven common requests that surprise people by getting refused, and for each one you’ll see why it’s blocked and the exact rephrase that clears it when the block isn’t a hard limit. Sort the permanent noes from the fixable ones and most of ChatGPT’s walls turn out to be softer than they look.
None of this means ChatGPT is broken or that you’ve done something wrong. Most of the things ChatGPT won’t do trace back to a cautious safety filter that would rather wrongly stop a harmless prompt than risk a harmful one. If you want the full reasons behind the behavior, our explainer on why ChatGPT refuses covers the mechanism in depth. This post is the practical companion to it: the specific requests that trip the filter, and what to actually do about each. If you’re newer to the tool, our beginner’s guide to ChatGPT is a good starting point too.
The 7 Things ChatGPT Won’t Do (Quick List)
Here’s the full list of things ChatGPT won’t do first, then the detail on each. Three are hard limits that never move, and four are usually false alarms you can reword around:
- Anything sexual involving minors:an absolute line, zero exceptions.
- Real weapons, explosives, or dangerous chemistry:how-to instructions are a hard no.
- Working malware or breaking into accounts:live attack code and account cracking.
- Specific medical, legal, or money advice:restricted since late 2025, but rewordable.
- Dark or violent fiction:often false-flagged; a clear frame fixes it.
- Security questions that sound like an attack:flip them to the defensive angle.
- Digging up information on a real person:a privacy block with a public-data workaround.
Full breakdown below, starting with the three that never budge.
Hard No or Fixable No? How to Tell the Difference
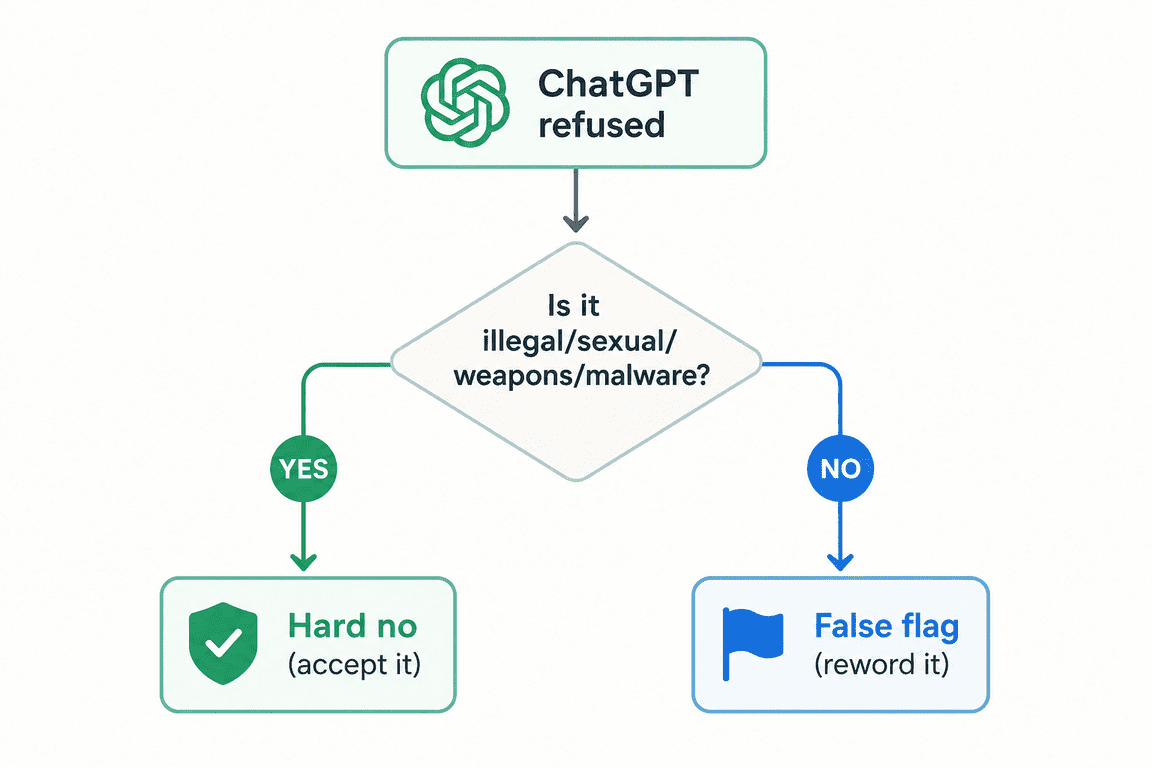
Before you fight any refusal, work out which kind you’re looking at, because only one kind responds to a rewrite. A hard no is about the content itself: the request is something OpenAI’s usage policies ban outright, so no phrasing will unlock it. A fixable no is about your wording: the request is legitimate, but it tripped the safety filter by accident, and a clearer ask sails through. Both are different from when ChatGPT stops responding entirely, which is a connection or server problem, not a refusal.
The quick test: would a reasonable person agree the request is genuinely dangerous or illegal? If yes, it’s a hard no and not worth pushing. If no, you’ve almost certainly hit a false flag, and the rest of this guide is about clearing those. This is the single most useful filter for understanding the things ChatGPT won’t do, because it tells you instantly whether to reword or walk away. If you want the deeper “won’t versus can’t” version of this distinction, the ChatGPT refusals explainer breaks it down further.
The Hard Noes ChatGPT Won’t Cross (No Matter How You Ask)
These three are permanent and the most important of the things ChatGPT won’t do to recognize on sight. They sit at the core of OpenAI’s rules, and rephrasing does nothing except waste your time and, if you keep hammering them, risk a warning on your account. The honest move here is to accept the no and move on.
1. Anything Sexual Involving Minors
This is the hardest line ChatGPT has, with zero exceptions and no “it’s fiction” carve-out. The model is built to refuse it instantly and report nothing back you can work with. There is no rephrase, no workaround, and no legitimate reason to look for one. Of all the things ChatGPT won’t do, this is the one to never test.
2. Real Weapons, Explosives, or Dangerous Chemistry
Asking for step-by-step instructions to build a weapon, an explosive, or a dangerous chemical or biological agent gets declined fast. General education is fine, so “how do nuclear reactors work” or “what’s the chemistry behind fireworks at a high level” is allowed. What’s blocked is anything that reads like a build guide for something that can hurt people. That distinction between concept and recipe is the line the filter watches.
3. Working Malware or Breaking Into Accounts
ChatGPT won’t write functioning malware, ransomware, or a live exploit, and it won’t help you get into an account, network, or device that isn’t yours. Learning how a type of attack works in theory is usually fine; producing a working tool to carry it out is not. If your security question keeps getting refused, that’s often a wording problem rather than a hard no, which is exactly the fixable case we cover below.
The False Flags a Rephrase Usually Fixes
These four are where most everyday frustration with the things ChatGPT won’t do actually lives. The request is perfectly reasonable, but something in the wording pattern-matches to risk and trips the filter. OpenAI knows this over-refusal happens and has been shifting toward what it calls safe-completions to cut down on needless noes, but the filter is still cautious, so a clear reword is your fastest fix. For each one, here’s the before and the after.
4. Specific Medical, Legal, or Money Advice
Since an October 2025 update to OpenAI’s Model Spec and usage policies, ChatGPT pulls back from tailored advice that really needs a licensed professional. Ask “what dose of this drug should I take” or “how should I word my custody filing” and you’ll often get a careful deflection. The fix is to ask for general information and keep the decision with a real professional.
- Before: “I have chest pain and shortness of breath, what medication and dose should I take?”
- After: “In general terms, what are common causes of chest pain with shortness of breath, and when should someone seek emergency care? I’ll see a doctor for my own situation.”
5. Dark or Violent Fiction
A villain’s monologue, a crime scene, or a tense thriller beat can pattern-match to harmful content even though it’s obviously fiction, because the filter reads patterns, not literary intent. Naming the creative purpose up front and asking for non-graphic, non-actionable detail usually clears it. The one real exception is explicit sexual content, which framing won’t fix.
- Before: “Write a scene where the killer explains exactly how he stalks his victim.”
- After: “I’m writing a crime thriller. Write the antagonist’s tense internal monologue as he follows someone, focused on dread and atmosphere, with no instructions a real person could copy.”
6. Security Questions That Sound Like an Attack
A student, a developer, or an IT admin can all ask a legitimate security question that the filter reads as an attack plan. The reliable fix is to flip the framing from offense to defense, and to ask conceptually rather than for a working tool.
- Before: “How do I hack into a Wi-Fi network?”
- After: “I’m studying for a security certification. How do attacks on WPA2 work at a conceptual level, and how would I configure a home network to defend against them?”
7. Digging Up Information on a Real Person
Ask ChatGPT to find a private individual’s address, phone number, or personal details and it refuses, because assembling private information about a real, identifiable person crosses a privacy line. You can still ask for legitimate, public ways to reach someone. If privacy is your wider concern, our guide on what you should never tell ChatGPT is worth a read.
- Before: “Find the home address and phone number for [person’s name].”
- After: “What are legitimate, public ways to contact a professional like a journalist or realtor, for example through an official website, a verified profile, or a public directory?”
The One Rephrase Move That Clears Most False Flags
If you only remember one fix, make it this: state who you are, why you’re asking, and what you actually want, in plain language, before the request. Visible intent is intent the filter can clear, and it turns most false flags into a normal answer on the next try. The same context-first habit is what keeps your prompts readable to any model, which we cover in how to write better AI prompts, and the same playbook works on other assistants too, like in our walkthrough on how to stop Claude refusing.
Two smaller moves help when context alone isn’t enough. Swap loaded keywords for plain ones and ask how something works rather than for steps to do it. And if a thread has started refusing everything, open a fresh chat, since a single early refusal often makes the model keep echoing it. None of this beats a hard no, but it clears the large majority of the fixable things ChatGPT won’t do.
The 7 at a Glance
Here are all seven of the things ChatGPT won’t do in one view, sorted by type with the move for each:
| The request | Hard no or fixable? | The move |
|---|---|---|
| Sexual content involving minors | Hard no | Never attempt it |
| Weapons / explosives / dangerous chemistry | Hard no | Ask concept-level only |
| Working malware / account cracking | Hard no | Ask how defense works instead |
| Tailored medical / legal / money advice | Fixable | Ask general info, see a pro |
| Dark or violent fiction | Fixable | Name the fiction, keep it non-graphic |
| Security “how to attack” questions | Fixable | Flip to the defensive angle |
| Finding a real person’s private info | Fixable | Ask for public contact methods |
The Short Version
So the things ChatGPT won’t do come in two flavors: a small set of permanent hard noes built into OpenAI’s rules, and a much larger set of false flags where a clear, context-first reword gets you a real answer. The skill is telling them apart in a second, then either accepting the no or rephrasing past it. Once I started sorting refusals this way, the walls stopped feeling random and most of them stopped being walls at all.
Keep your prompts specific, lead with your intent, and you’ll rarely hit one of the fixable things ChatGPT won’t do twice. The hard limits are there for good reason and aren’t worth fighting. If you’re choosing between assistants and refusals are your deciding factor, our comparison of which one refuses more is the next read, and the same behavior on Anthropic’s side is covered in why Claude refuses questions. The full picture, why every chatbot does this, is in our explainer on why AI chatbots refuse.