

Last reviewed: June 2, 2026
This article compares paid AI subscriptions and API usage, from $20 a month up to enterprise spend. It is for educational purposes only, not financial advice. Prices and benchmarks in this category move fast, so confirm the current numbers on Anthropic’s and OpenAI’s official pages before you commit a budget or migrate a workload.
Claude Opus 4.8 vs GPT-5.5 is the closest flagship matchup of 2026: on aggregate intelligence benchmarks the two sit within a point or two of each other, and both cost $20 a month on the consumer plan. After running both on the same coding, writing, and agent taskOpus 4.8 is the better engine for coding, code review, and reliable long-running agents.
s since Opus 4.8 launched on May 28, my honest verdict is that the winner comes down to one thing, what you do most. Opus 4.8 wins real-world software engineering (69.2% vs 58.6% on SWE-bench Pro), code review, and agent reliability. GPT-5.5 wins terminal and CLI automation, runs leaner on tokens, and brings the broader everyday ecosystem (voice, image generation, plugins, live web). On price, both charge $5 per million input tokens, but Claude’s output is cheaper at $25 against $30. For developers, Opus 4.8 is the smarter pick. For one app that does a bit of everything, GPT-5.5 still leads.
Quick Verdict: Claude Opus 4.8 vs GPT-5.5 at a Glance
If you write code for a living, pick Claude Opus 4.8. If you want one assistant that also makes images, talks back, and browses the live web, pick GPT-5.5. That is the whole Claude Opus 4.8 vs GPT-5.5 decision in two sentences, and for most people it really is that clean. The two models are close enough on raw intelligence that the tie-breaker is your daily workload, not a benchmark leaderboard.
| If your main job is… | Pick | Why |
|---|---|---|
| Software engineering, code review | Claude Opus 4.8 | Leads SWE-bench Pro by ~11 points, ~4x fewer missed code flaws |
| Terminal / CLI / DevOps automation | GPT-5.5 | Keeps a small lead on terminal-style benchmarks, runs leaner |
| Images, voice, plugins, live web | GPT-5.5 | Native multimodal and the biggest ecosystem; Claude has none of these |
| Long agentic jobs, reliability | Claude Opus 4.8 | Higher OSWorld score plus Dynamic Workflows in Claude Code |
| Lowest token cost per task | Roughly even | Claude is cheaper per output token; GPT-5.5 is more concise |
The rest of this Claude Opus 4.8 vs GPT-5.5 breakdown is the evidence behind that table: what each model is, the head-to-head numbers, where each one actually wins, and the real pricing math for a $20 subscriber and an API user.
What Is Claude Opus 4.8?
Claude Opus 4.8 is Anthropic’s flagship model, released May 28, 2026. It leads the public field on agentic coding, scoring 88.6% on SWE-bench Verified and 69.2% on SWE-bench Pro, and it adds Dynamic Workflows in Claude Code, which lets the model run hundreds of parallel subagents on one task. Standard API pricing is $5 input and $25 output per million tokens.
The headline improvement over the previous version is reliability: roughly 4x fewer missed code flaws and a stronger habit of flagging uncertainty instead of bluffing, per Anthropic’s launch announcement. If you are deciding between this and the model it replaced rather than against GPT-5.5, we cover that in our Claude Opus 4.8 vs Opus 4.7 upgrade guide, and the standalone deep dive lives in our full Claude Opus 4.8 review.
What Is GPT-5.5?
GPT-5.5 is OpenAI’s flagship model, released April 23, 2026, and still the current top model as of June (GPT-5.6 is rumored but not shipped). It is built for long, multi-step agentic work: writing and debugging code, browsing the live web, operating software, and moving across tools until a task is done. ChatGPT Plus includes it for $20 a month, and the API runs $5 input and $30 output per million tokens.
GPT-5.5’s real strengths over Claude are breadth and autonomy in the terminal. It has native voice mode, image generation, a huge library of plugins and Custom GPTs, and real-time search, none of which Claude offers, per OpenAI’s GPT-5.5 announcement. It also tends to be more concise, finishing tasks in fewer output tokens. For how it improved on the prior OpenAI release, see our GPT-5.5 vs GPT-5.4 breakdown.
Claude Opus 4.8 vs GPT-5.5: Head-to-Head Benchmarks

On aggregate intelligence the two are essentially tied, landing within a point or two of each other at the top of the public leaderboards. The Claude Opus 4.8 vs GPT-5.5 gaps only get interesting when you split by task: Claude pulls ahead on real-world software engineering, GPT-5.5 holds the terminal, and they trade the rest. Here are the launch-window numbers from each lab.
| Benchmark / capability | Claude Opus 4.8 | GPT-5.5 | Edge |
|---|---|---|---|
| SWE-bench Pro (agentic coding) | 69.2% | 58.6% | Opus 4.8 (big) |
| SWE-bench Verified | 88.6% | ~80% | Opus 4.8 |
| Terminal-Bench (CLI tasks) | Strong | Leads (small margin) | GPT-5.5 |
| OSWorld (computer use) | ~83% | ~79% | Opus 4.8 |
| Aggregate intelligence index | ~61 | ~60 | Roughly tied |
| Output tokens per task | More verbose | Leaner | GPT-5.5 |
Treat the small gaps as ties. The two clear, repeatable findings in this Claude Opus 4.8 vs GPT-5.5 comparison are the SWE-bench Pro lead for Claude (about 11 points) and the terminal lead for GPT-5.5. The earlier-generation version of this fight, when GPT-5.5 launched against Opus 4.7, is in our GPT-5.5 vs Claude Opus 4.7 comparison, and 4.8 has only widened Claude’s coding edge since.
Coding: Where Opus 4.8 Pulls Ahead
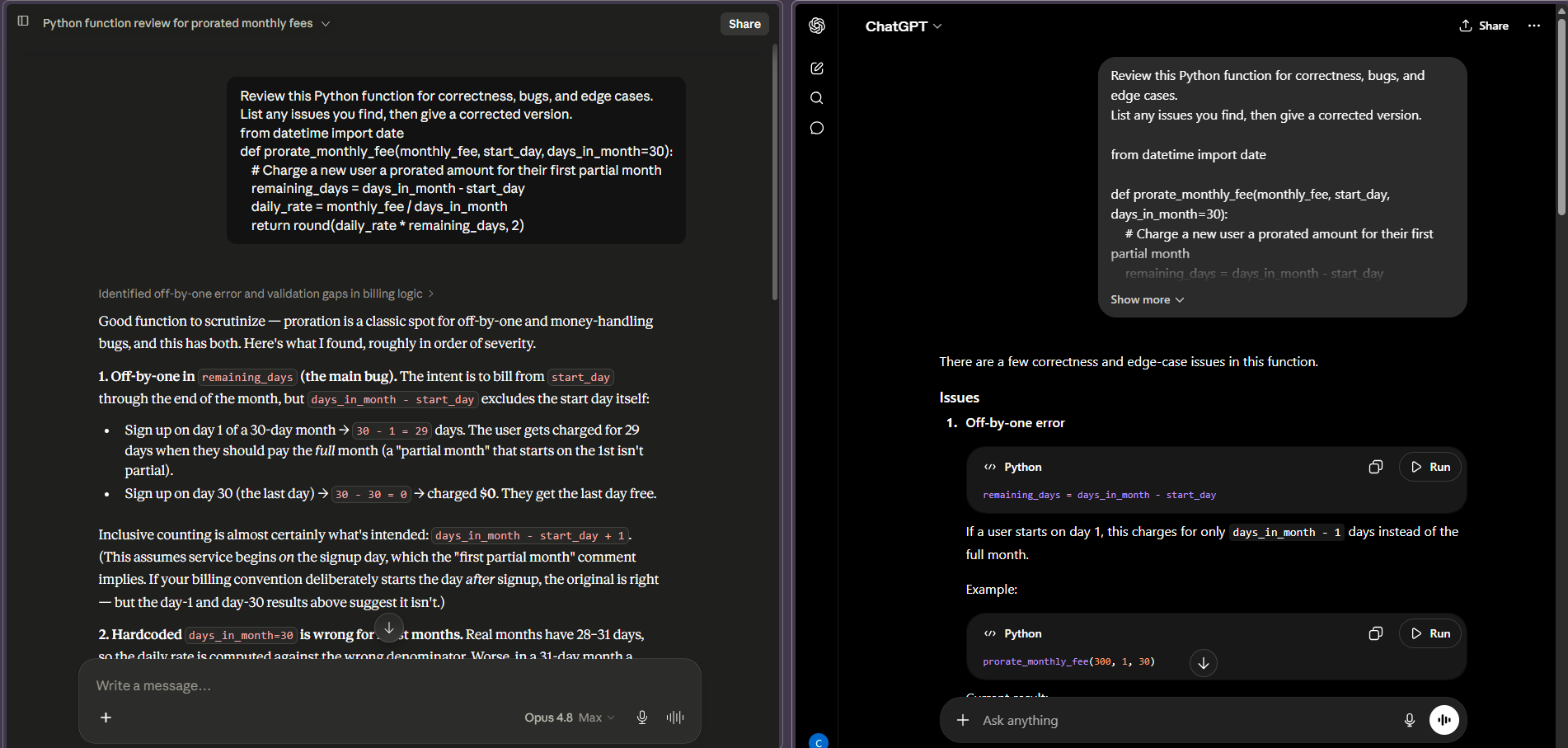
For real software engineering, Claude Opus 4.8 is the stronger model, and the gap shows up most in multi-file work and code review rather than quick snippets. The Claude Opus 4.8 vs GPT-5.5 benchmark spread (69.2% vs 58.6% on SWE-bench Pro) matches what I saw running both on the same tasks: Claude ships more end-to-end features that actually pass tests on the first try.
The test that separated them for me was a refactor across a handful of files with a deliberately planted edge case. I gave both the same prompt. GPT-5.5 was faster to a first answer and wrote tidy code, but it missed the edge case and one cross-file import. Opus 4.8 was a touch slower, caught the edge case, flagged the import conflict, and asked one clarifying question before finishing. GPT-5.5 is genuinely excellent at terminal-driven and DevOps automation, where it still holds a small benchmark lead and its leaner output saves tokens. But for shipping reviewed, production-ready code, Claude’s reliability edge is the thing you feel every day. That advantage compounds on long agentic jobs, which lines up with the shift toward autonomous, resumable agents we covered in our guide to AI agents.
Everyday Use, Writing, and Multimodal: Where GPT-5.5 Wins
For everything that is not pure coding, the Claude Opus 4.8 vs GPT-5.5 verdict flips: GPT-5.5 is the more complete product, and it is not close on breadth. Claude Opus 4.8 has no image generation, no voice mode, no plugin store, and only limited live web access. GPT-5.5 has all of it built in, which makes it the better single subscription for general work.
On writing, it is closer than the feature list suggests. In my testing both draft clean prose, but they have different default voices: Claude tends to read more natural and considered on long-form and technical writing, while GPT-5.5 is crisper for marketing copy and can generate an image in the same chat. If your day is research, content, voice notes, and the occasional image, GPT-5.5 covers more ground from one window. If you mostly write code and documents and care about a natural voice, Claude is the better writer of the two. For the wider Anthropic-versus-OpenAI picture beyond these two models, our Claude vs ChatGPT 2026 comparison goes deeper on the ecosystem trade-offs.
Pricing: The Real $20 and the API Math

On the consumer plan, the Claude Opus 4.8 vs GPT-5.5 price is a tie: both Claude Pro and ChatGPT Plus cost $20 a month. The difference is what is bundled (Claude includes Claude Code; ChatGPT includes image generation, voice, and plugins) and what you pay on the API, where the two have quietly converged on input price but still split on output.
| What you pay | Claude Opus 4.8 | GPT-5.5 | Cheaper |
|---|---|---|---|
| Consumer plan | $20/mo (Claude Pro) | $20/mo (ChatGPT Plus) | Tie |
| API input (per 1M) | $5 | $5 | Tie |
| API output (per 1M) | $25 | $30 | Claude |
| Batch output (per 1M) | $12.50 | $15 | Claude |
| Cached input (per 1M) | $0.50 | $0.50 | Tie |
The honest pricing read on Claude Opus 4.8 vs GPT-5.5: input is now identical at $5 per million tokens, so the gap is all on output, where Claude is 17% cheaper at $25 against GPT-5.5’s $30. GPT-5.5 narrows that in practice because it tends to generate fewer output tokens per task, so on token-sensitive, high-volume workloads the real-world cost can land close. For chatty, long-output coding sessions, Claude is the cheaper model per finished task. GPT-5.5’s full API rates are on OpenAI’s pricing page.
When to Use Each
Match the model to your dominant task and the choice is easy. Here is the practical split for the Claude Opus 4.8 vs GPT-5.5 decision based on what you actually do most days.
- Pick Claude Opus 4.8 if you write code seriously, do multi-file refactors or code review, run long agentic coding jobs, or want the most natural voice for technical and long-form writing.
- Pick GPT-5.5 if you want one assistant for everything: image generation, voice mode, plugins, real-time web, plus strong terminal and DevOps automation.
- Pick GPT-5.5 if you run high-volume, token-sensitive workloads where its leaner output and concise style keep the bill down.
- Run both ($40/month) if AI is core to your work: Claude for coding and writing, GPT-5.5 for everything multimodal. They cover each other’s blind spots.
- Adding Gemini to the shortlist? Our ChatGPT vs Claude vs Gemini pillar covers the full three-way decision and pricing math.
Claude Opus 4.8 vs GPT-5.5 FAQ
Is Claude Opus 4.8 better than GPT-5.5 for coding?
Yes for most software engineering. Claude Opus 4.8 scores 69.2% on SWE-bench Pro versus GPT-5.5’s 58.6%, ships more working first-try code on multi-file tasks, and catches roughly 4x more of its own flaws. GPT-5.5 still leads on terminal and CLI automation by a small margin and uses fewer output tokens, so it is the better pick for DevOps scripting and token-sensitive automation.
Is GPT-5.5 cheaper than Claude Opus 4.8?
It depends on the workload. Both cost $20 a month on the consumer plan and $5 per million input tokens on the API. Claude is cheaper on output ($25 vs $30 per million), but GPT-5.5 tends to generate fewer output tokens per task, which can close the gap on high-volume jobs. For long-output coding sessions, Claude usually costs less per finished task.
Which is smarter overall, Opus 4.8 or GPT-5.5?
They are effectively tied on aggregate intelligence, sitting within a point or two of each other at the top of the public benchmarks. The meaningful differences are by task, not overall: Claude leads real-world coding and agent reliability, GPT-5.5 leads terminal work, multimodal features, and ecosystem breadth.
Does GPT-5.5 have features Claude Opus 4.8 lacks?
Yes, several. GPT-5.5 has native image generation, advanced voice mode, real-time web search, and a large library of plugins and Custom GPTs. Claude Opus 4.8 has none of those. Claude’s edge is the other direction: stronger coding, code review, agent reliability, and Dynamic Workflows in Claude Code.
Should I switch from GPT-5.5 to Claude Opus 4.8?
Switch if your main job is coding or technical writing, where Claude is clearly stronger. Stay on GPT-5.5 if you rely on images, voice, plugins, or live web, since Claude cannot replace those. Many heavy users run both at $40 a month and route coding to Claude and everything multimodal to GPT-5.5.
Is there a newer model than GPT-5.5 or Opus 4.8?
Not yet, as of June 2026. GPT-5.5 (April 2026) and Claude Opus 4.8 (May 28, 2026) are the current flagships from OpenAI and Anthropic. GPT-5.6 has leaked in prediction markets and codenames but is not officially released, so this Claude Opus 4.8 vs GPT-5.5 matchup is the live one to compare today.
Final Verdict
After putting both through the same work, my honest call on Claude Opus 4.8 vs GPT-5.5 is that there is no single winner, only a winner for you. The two are tied on raw intelligence and identical at $20 a month, so the decision is genuinely about your dominant task. Opus 4.8 is the better engine for coding, code review, and reliable long-running agents, and we put exactly that to the test in our deep dive on Claude Opus 4.8 for coding. GPT-5.5 is the better all-in-one for images, voice, plugins, live web, and lean terminal automation.
My practical advice: if you ship code, make Claude Opus 4.8 your daily driver and keep ChatGPT free in the other tab for the multimodal extras. If you live across research, content, and a bit of everything, GPT-5.5 is the smarter single $20. And if AI is central to how you work, $40 a month for both is the setup most professionals I know land on, because each model quietly covers the other’s weak spots. For where this whole race is heading, the same pattern from our three-way flagship comparison holds: the models are close enough now that the real question is not which is smartest, but which one fits the work in front of you.



