

Last reviewed: June 1, 2026
This article covers an upgrade decision for paid AI subscriptions and API usage, from $20 a month up to enterprise contracts. It is for educational purposes only, not financial or technical advice. Model pricing and features in this category change fast, so confirm the current numbers on Anthropic’s official pricing page before you migrate a production workload.
Claude Opus 4.8 vs Opus 4.7 comes down to one question for existing users: is the upgrade worth the switch? After running both on the same coding work since Anthropic’s May 28 launch, my honest answer is yes for almost everyone, and the reason is that it costs you nothing. Standard pricing is identical at $5 input and $25 output per million tokens, the two models share the same tokenizer so your token counts do not change, and the only thing you swap is the model name. What you gain is real: a jump from 64.3% to 69.2% on SWE-bench Pro, roughly 4x fewer missed code flaws, a Fast mode that is three times cheaper, and the new Dynamic Workflows feature in Claude Code. The one reason to wait is a production system pinned to 4.7 that needs a smoke test first.
The Honest Question Before You Upgrade
For almost everyone already on Anthropic’s stack, the Claude Opus 4.8 vs Opus 4.7 decision is a yes, and you should switch today. The upgrade is free, pricing is the same at the Standard tier, and the only thing that changes in your code is the model string. The honest version of the question is not “is 4.8 better” (it clearly is), it is “is anything I depend with medium as the money-saver for routine ticketson with medium as the money-saver for routine tickets. We dig into how it holds up across a week of real coding in our Claude Opus 4.8 coding guide. going to break when I switch”, and for the vast majority of people the answer is no.
Anthropic shipped Opus 4.8 just 41 days after Opus 4.7, the fastest major model turnaround in the company’s history. TechCrunch framed the quick cycle as a response to a lukewarm reception for 4.7, which tracks with how this release feels in practice: it is less a reinvention than a sharpening of what 4.7 already did well. If you want the full standalone breakdown of the new model on its own terms, we covered that in our full Claude Opus 4.8 review. This post is narrower. It is only about whether 4.7 users should move.
Claude Opus 4.7 in One Paragraph
To frame the Claude Opus 4.8 vs Opus 4.7 question fairly, start with what 4.7 already got right. Opus 4.7 was the model that made multi-hour agentic coding feel reliable instead of experimental. It launched in mid-April 2026, scored 87.6% on SWE-bench Verified and 64.3% on SWE-bench Pro, and introduced the new tokenizer and the xhigh effort level that 4.8 still uses today. The thing people complained about, and the thing I flagged in our Claude Opus 4.7 review, was a habit of writing confident code that quietly broke at the edges. It was a strong model with one real weakness: it did not always know when it was wrong.
Claude Opus 4.8 in One Paragraph
Opus 4.8 is that same model with the edges sanded down and one genuinely new trick. It nudges the coding benchmarks up (69.2% on SWE-bench Pro), cuts missed code flaws by roughly 4x on Anthropic’s internal evals, and is, per Anthropic’s launch announcement, more likely to flag uncertainty instead of bluffing. The new trick is Dynamic Workflows in Claude Code, which lets the model plan a task and then fan out hundreds of parallel subagents in a single session. Everything else, the price, the tokenizer, the context window, the effort levels, is carried straight over from 4.7. That is the whole point of the Claude Opus 4.8 vs Opus 4.7 story: same foundation, fewer mistakes.
The 5 Things That Actually Changed
The Claude Opus 4.8 vs Opus 4.7 difference is five concrete changes, not a top-to-bottom rebuild. If you want the short version before the detail, here they are in order of how much they mattered in my testing:
- Dynamic Workflows in Claude Code: the model writes its own orchestration script and runs parallel subagents (4.7 cannot do this)
- Roughly 4x fewer missed code flaws: the single most useful change for real work
- Coding benchmark gains: SWE-bench Pro up from 64.3% to 69.2%, Verified up from 87.6% to 88.6%
- Fast mode is 3x cheaper: $10/$50 per million tokens instead of $30/$150
- Zero migration cost: same price, same tokenizer, only the model name changes
The headline of the Claude Opus 4.8 vs Opus 4.7 upgrade is Dynamic Workflows, and it is the one thing 4.7 genuinely cannot match. Inside Claude Code, 4.8 can plan a large job, write a short JavaScript orchestration script, and run up to 16 parallel subagents at once (1,000 total per run) against your test suite. It ships in research preview on Max, Team, and Enterprise plans. The smaller detail that won me over: if you kill the terminal mid-run, 4.8 resumes from where it stopped instead of starting over. That single behavior is what makes long autonomous jobs feel safe to actually use, and it lines up with the shift toward stateful agents we wrote about in our guide to AI agents.
The second change matters more than its modest benchmark bump suggests. The 4x reduction in missed flaws is the difference between code review you have to redo and code review you can trust. More on that in the testing section, because it is the part of the Claude Opus 4.8 vs Opus 4.7 comparison that actually changed how I work.
The Benchmarks That Actually Moved

On published coding benchmarks, the Claude Opus 4.8 vs Opus 4.7 gap is real but honest: Opus 4.8 leads 4.7 across the board, yet the margins are modest rather than dramatic. The biggest single jump is SWE-bench Pro, the agentic coding benchmark, where 4.8 scores 69.2% against 4.7’s 64.3%. Everything else is a smaller step up. Here is the side-by-side using Anthropic’s own published numbers from launch.
| Benchmark / feature | Claude Opus 4.8 | Claude Opus 4.7 | What it means |
|---|---|---|---|
| SWE-bench Pro (agentic) | 69.2% | 64.3% | +4.9 points, the biggest real gain |
| SWE-bench Verified | 88.6% | 87.6% | +1.0 point, near the ceiling already |
| Missed code flaws (internal) | ~4x fewer | Baseline | The change you feel most in daily use |
| Dynamic Workflows | Yes | No | Parallel subagents in Claude Code |
| Tokenizer | Shared with 4.7 | Shared with 4.8 | Same token counts, no cost surprise |
The takeaway from the Claude Opus 4.8 vs Opus 4.7 numbers is that this is an incremental capability upgrade with one structural addition. If you were hoping for a generational leap, this is not it. If you wanted 4.7 to stop making the same class of mistakes, that is exactly what landed. For how Opus stacks up against OpenAI’s flagship rather than its own predecessor, see how it stacks up against GPT-5.5 in our Claude Opus 4.8 vs GPT-5.5 comparison, and the previous-generation matchup is in our GPT-5.5 vs Claude Opus 4.7 comparison.
The Pricing Difference (Standard, Fast Mode, Agents)
Pricing is the easiest part of the Claude Opus 4.8 vs Opus 4.7 comparison: at the Standard tier, there is no difference at all. Opus 4.8 costs the same $5 input and $25 output per million tokens that 4.7 did. The real change is Fast mode, which drops from $30/$150 to $10/$50 for the same 2.5x speed boost. Because both models share a tokenizer, the same prompt produces the same token count on each, so switching does not quietly inflate your bill.
| Tier | Claude Opus 4.8 | Claude Opus 4.7 | Difference |
|---|---|---|---|
| Standard (input / output per 1M) | $5 / $25 | $5 / $25 | Identical |
| Fast mode (input / output per 1M) | $10 / $50 | $30 / $150 | 3x cheaper on 4.8 |
| Batch API (input / output per 1M) | $2.50 / $12.50 | $2.50 / $12.50 | Identical |
| Cache read (per 1M) | $0.50 | $0.50 | Identical |
| Managed Agents runtime | + $0.08 / session-hour | + $0.08 / session-hour | Same stateful-agent rate |
Anthropic’s own worked example puts a one-hour Opus 4.8 coding session (50,000 input and 15,000 output tokens) at $0.705, dropping to $0.525 with prompt caching active. That is the same math you were already running on 4.7. So the honest pricing read on Claude Opus 4.8 vs Opus 4.7 is simple: you pay the same, you get more, and if you ever needed Fast mode but found it too expensive on 4.7, that door just opened.
How I Tested Both, and Where 4.8 Pulled Ahead
I leaned on Opus 4.7 daily since it launched in April, so for this Claude Opus 4.8 vs Opus 4.7 comparison I ran my actual recent work back through 4.8 over the days since the May 28 launch and watched for the differences. The clearest gap showed up in code review, not in raw generation. The two models write similar-quality code on a first pass. They diverge on whether they catch their own mistakes.
The test that made the Claude Opus 4.8 vs Opus 4.7 difference obvious for me was a small one. I handed both the same date-parsing function with a subtle timezone bug that only triggers on daylight-saving boundaries, and asked each to review and fix it. Opus 4.7 produced a clean-looking rewrite that preserved the bug. Opus 4.8 flagged the timezone handling on the first read, asked which behavior I actually wanted, and shipped two options with the trade-offs labeled. Same prompt, same code, very different instinct. That “more likely to flag uncertainty” claim from the launch notes is not marketing, it is the thing you notice first.
The second place 4.8 pulled ahead was Dynamic Workflows on a larger job. I pointed Claude Code at a framework upgrade spanning a couple hundred files, the kind of chore that used to eat a full afternoon across several 4.7 sessions. With 4.8, it planned the work, fanned out parallel subagents against the test suite, and when I deliberately closed the terminal halfway through, it picked the job back up instead of restarting. None of that is possible on 4.7. Effort control behaved the same on both, by the way: xhigh stays the right default for coding per Anthropic’s effort guidance, with medium as the money-saver for routine tickets.
Who Should Upgrade to Claude Opus 4.8 (and Who Can Wait)
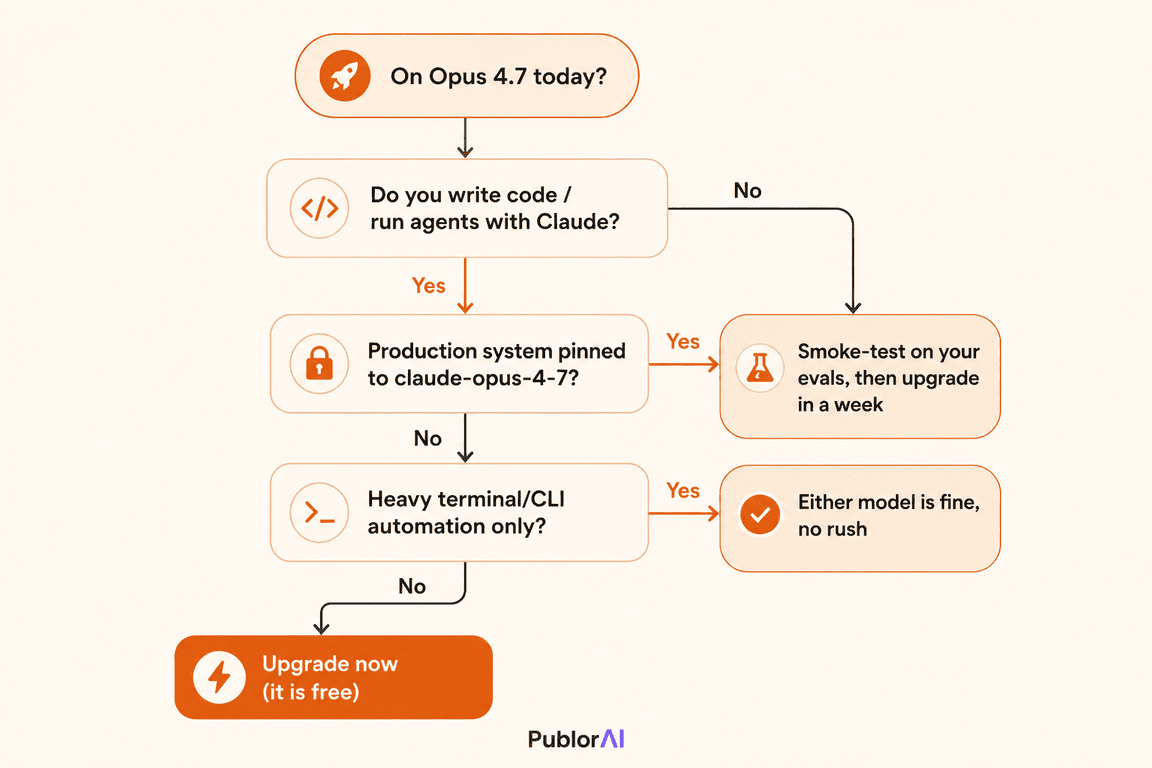
Almost everyone should upgrade, and most people can do it right now with no preparation. The upgrade is free, the behavior is strictly better for coding, and the only real risk is in pinned production systems that deserve a quick test first. Here is the honest breakdown for the Claude Opus 4.8 vs Opus 4.7 switch.
- Upgrade today if you write code with Claude, run agents, use Claude Code, or pay for Claude Pro or Max. It is free, code reliability is meaningfully better, and Dynamic Workflows alone earns the switch.
- Upgrade today if you ever wanted Fast mode on 4.7 but found $30/$150 too steep. At $10/$50, it becomes a realistic option for latency-sensitive work.
- Wait about a week if you have a production system pinned to
claude-opus-4-7. Let the early reports settle, run a smoke test on your own evals, then migrate. The switch is just the model string. - No rush if your workload is almost entirely terminal or CLI automation, where the gap is smallest. You lose nothing by moving, but you are not leaving much on the table by waiting either.
- If you are weighing Claude against ChatGPT rather than against itself, our ChatGPT vs Claude vs Gemini comparison covers the wider feature picture, since 4.8 does not change the non-coding tradeoffs.
Claude Opus 4.8 vs Opus 4.7 FAQ
Is Claude Opus 4.8 worth upgrading from Opus 4.7?
Yes for almost everyone. The upgrade is free, Standard pricing is identical, the two models share a tokenizer so token counts do not change, and you only swap the model name. You gain about 4x fewer missed code flaws, a 4.9-point bump on SWE-bench Pro, a 3x-cheaper Fast mode, and Dynamic Workflows. The only reason to wait a week is a production system pinned to the 4.7 model string that needs a smoke test first.
Does Claude Opus 4.8 cost more than Opus 4.7?
No. Standard pricing is the same: $5 per million input tokens and $25 per million output tokens on both. Batch and cache-read rates are identical too. The one price that changed dropped in your favor: Fast mode is now $10/$50 instead of 4.7’s $30/$150, a 3x cut for the same 2.5x speed.
What is the biggest difference between Opus 4.8 and Opus 4.7?
Two things. Day to day, it is reliability: Opus 4.8 catches roughly 4x more of its own code flaws and flags uncertainty instead of bluffing. Structurally, it is Dynamic Workflows in Claude Code, which lets 4.8 run hundreds of parallel subagents on one task and resume after an interruption. Opus 4.7 cannot do that.
Do I need to change my code to switch from 4.7 to 4.8?
Only the model name. The endpoint pattern moves from claude-opus-4-7 to claude-opus-4-8, and that is the whole migration for most users. There is no new tokenizer, no prompt rewrite, and no pricing change at the Standard tier. If you have pinned 4.7 in production, run your existing eval suite once before flipping it.
Is Opus 4.8 a big upgrade or just a version bump?
The Claude Opus 4.8 vs Opus 4.7 jump is an incremental upgrade with one structural addition. The benchmark gains are modest (a point or two in most places, about five on SWE-bench Pro), so it is not a generational leap. But the reliability improvement and Dynamic Workflows make it feel meaningfully better in real coding work, and since it is free, the version-bump framing misses the point: there is no reason not to take it.
Can I still use Opus 4.7 after 4.8 launches?
Yes. Opus 4.7 remains available on the API at the same pricing, so pinned production systems keep working. Anthropic typically keeps a previous Opus version live well after a new one ships. There is no forced migration, but new work should default to 4.8.
Final Verdict: My Honest Upgrade Call
If I had to settle the Claude Opus 4.8 vs Opus 4.7 question in one line, it is this: take the upgrade, because it asks nothing of you and gives back a model that makes fewer mistakes. The benchmarks moved a little, the reliability moved a lot, and Dynamic Workflows opens a workflow that simply did not exist on 4.7. None of it costs more, and the only friction is a one-line model-name change.
The part I keep coming back to is the 41-day gap between these two releases. That pace is the real story here, more than any single benchmark. Anthropic is now iterating fast enough that “should I upgrade” is becoming a question you answer every few weeks instead of once a year, and the honest default answer, when the upgrade is free and strictly better, is just yes. Switch today, keep xhigh as your coding default, and budget for a small token-spend bump only if you start leaning on Dynamic Workflows hard. For where this whole category is heading, the same pattern we traced in our look at AI agents keeps playing out: the models are getting reliable enough that the question stops being “can it do this” and becomes “which version do I trust to do it for me.”



